
Les systèmes d'exploitation/Assembleur et édition des liens

La majorité des programmes actuels sont écrits dans des langages de haut niveau, comme le C, le Java, le C++, l'Erlang, le PHP, etc. Mais ces langages ne sont pas compréhensibles par le processeur, qui ne comprend que le langage machine. Les codes sources écrits dans des langages de haut niveau doivent donc être traduit en langage machine par la chaîne de compilation. À l'heure actuelle, la majorité des compilateurs ne traduit pas directement un langage de haut niveau en langage machine, mais passe par un langage intermédiaire : l'assembleur. Cet assembleur est un langage de programmation, utilisé autrefois par les programmeurs, assez proche du langage du langage machine. Il va de soit que cet assembleur doit être traduit en langage machine pour être exécuté par le processeur. Tout ce qui se passe entre la compilation et l'exécution du programme est pris en charge par trois programmes qui forment ce qu'on appelle la chaîne d'assemblage. Cette chaîne d'assemblage commence par le logiciel d'assemblage qui traduit le code assembleur en code machine. Ce code machine est alors mémorisé dans un fichier objet. Ensuite, l'éditeur de liens, ou linker, qui combine plusieurs fichiers objets en un fichier exécutable. Enfin, le chargeur de programme, aussi appelé loader, charge les programmes en mémoire. L'ensemble regroupant compilateur et chaîne d'assemblage, avec éventuellement des interpréteurs, est appelé la chaîne de compilation.
- La chaine de compilation
-
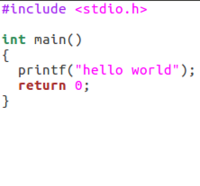 Un programme écrit dans un langage de haut niveau (le C, en l’occurrence).
Un programme écrit dans un langage de haut niveau (le C, en l’occurrence). -
 Le code assembleur.
Le code assembleur. -
 Le programme en langage machine.
Le programme en langage machine.



Traduire les l'assembleur en instructions-machine est la première tâche du logiciel d'assemblage, mais ce n'est pas la seule. Il s'occupe aussi de la résolution des symboles, à savoir qu'il transforme les labels (et autres symboles) en adresses mémoires (l'adresse de l'instruction cible d'un branchement, ou adresse d'une variable). Pour détailler plus, il faut faire la différence entre les symboles locaux, utilisés uniquement dans le module où ils sont définis (ils servent à fabriquer des fonctions, variables statiques et structures de contrôle), des symboles globaux, référencés dans d'autres fichiers (ils servent pour nommer les fonctions accessibles à l'extérieur du module, et les variables globales). De plus, la chaîne d’assemblage doit s'occuper en partie de la relocation, même si cela dépend fortement du processeur. Les contraintes d'alignement mémoire, la taille variable des instructions, et les modes d'adressages utilisés vont devoir être pris en compte lors du processus de relocation. Évidemment, les logiciels de la chaîne d'assemblage peuvent aussi optimiser le code assembleur généré, de manière à le rendre plus rapide. Mais nous passerons cette fonctionnalité sous silence dans ce qui suit.
Le logiciel d'assemblage
[modifier | modifier le wikicode]
L'assembleur permet, comme le langage machine, d'utiliser directement le instructions du jeu d'instruction, mais dans une version nettement plus facile pour les êtres humains. Au lieu d'écrire ces instructions sous la forme de suites de bits, la programmation en assembleur décrit chaque instruction en utilisant du texte. Ainsi, les opérandes peuvent être écrites en décimal, au lieu de devoir être écrites en binaires. De plus, les opcodes sont remplacées par un mot : la mnémonique. Pour donner un exemple, l’instruction d'addition aura pour mnémonique ADD, ce qui est plus facile à taper que le code binaire correspondant. Il existe aussi des mnémoniques pour les registres, qui portent le nom de noms de registres. Par exemple, l'assembleur x86 nomme les registres avec les mnémoniques EAX, EBX, ECX, EDX, etc. Les modes d'adressages sont pris en charge via des syntaxes spéciales. Il est aussi possible de nommer une ligne de code (une instruction, donc) en lui attribuant un label, qui est remplacé par l'adresse de l'instruction lors de la traduction en langage machine. Ces labels sont utiles pour remplacer l'adresse de destination des branchements, ce qui permet de ne pas écrire ces adresses en dur.
Certains assembleurs permettent aussi de créer des macros, des ancêtres des fonctions. Ces macros sont simplement des suites d'instructions qui sont nommées. Il est possible d'insérer ces macros n'importe où dans le code, en mettant leur nom à cet endroit en utilisant une syntaxe spéciale. La suite d'instruction sera alors recopiée à l'endroit où le nom de la macro a été inséré, lors de la traduction en langage machine. Cela évite d'avoir à faire des copier-coller.
Le logiciel d'assemblage traduit chaque ligne de code l'une après l'autre. Cela demande de :
- remplacer la mnémonique par l'opcode correspondant ;
- remplacer les opérandes par la suite de bits correspondante ;
- remplacer les labels par l'adresse qui correspond ;
- remplacer les macros par leur contenu ;
- ne rien faire sur les commentaires.
Il faut cependant noter que les langages assembleurs ne sont pas forcément rudimentaires. Il existe notamment des assembleurs de haut-niveau, qui gèrent structures de contrôle, fonctions, procédures, types de données composites (structures et unions), voire la programmation orientée objet par classes. Ceux-ci demandent d'ajouter une phase de compilation en assembleur « pur » à un logiciel d'assemblage plus rudimentaire.
Macros
[modifier | modifier le wikicode]La première opération que va faire le logiciel d'assemblage est le remplacement [appel de macro → corps de la macro]. Ces macros sont sauvegardées dans une table de hachage qui associe un nom de macro à son corps : la table des macros. Cependant, les choses deviennent beaucoup plus compliquées quand les macros contiennent des arguments/paramètres, ou quand le logiciel d'assemblage utilise des macros imbriquées ou récursives. Pour effectuer ce remplacement, le logiciel d'assemblage peut procéder en une ou deux étapes, la situation la plus simple à comprendre étant celle à deux étapes.
Un assembleur à deux étapes (on peut aussi dire : à deux passes) procède comme suit : la première étape parcourt le code assembleur pour détecter les macros, alors que la seconde effectue le remplacement. L'algorithme de la première passe lit le fichier source ligne par ligne. Si une ligne est une macro, il crée une entrée dans la table des macros et copie les lignes de code suivantes dans celle-ci. Il continue ainsi jusqu'à tomber sur le mot-clé qui indique la fin du corps de la macro. C'est aussi lors de cette passe que sont gérées les directives. Par la suite, le logiciel d'assemblage va effectuer le remplacement, qui ne peut pas se faire « en place » : le logiciel d'assemblage doit copier le fichier source dans un nouveau fichier.
Certains assembleurs forcent la déclaration des macros en début de fichier, juste avant le code principal. Dans ce cas, les macros sont toutes déclarées avant leur utilisation, ce qui permet de fusionner ces deux passes en une seule : c'est la passe 0.
- Lire une ligne de code dans le fichier source ;
- Si cette ligne est un nom de macro, créer une entrée dans la table des macros, et copier les lignes de code suivantes dans celle-ci jusqu'à tomber sur le mot-clé qui indique la fin du corps de la macro : à ce moment-là, on retourne à l'étape 1 ;
- Si cette ligne est une directive qui peut être gérée lors de la passe 0, l'exécuter, puis retourner à l'étape 1 ;
- Si cette ligne est une instruction-machine, copier celle-ci dans le nouveau fichier source (sauf s'il s'agit de la ligne qui indique la fin du programme) ;
- Sinon, accéder à la table des macros et copier le corps de la macro ligne par ligne dans le nouveau fichier.
- Si cette ligne indique la fin du code source, arrêter là.
Mnémoniques
[modifier | modifier le wikicode]Pour traduire les mnémoniques en opcode, le logiciel d'assemblage contient une table de hachage mnémonique → opcode : la table des opcodes. Cette table associe à chaque mnémonique l'opcode qui correspond, éventuellement la taille de l'opcode pour les architectures à instructions de taille variable ou d'autres informations. Il se peut qu'une mnémonique corresponde à plusieurs instructions-machine, suivant le mode d'adressage. Dans ce cas, chaque entrée de la table des mnémoniques contient plusieurs opcodes, le choix de l'opcode étant fait selon le mode d'adressage. Identifier le mode d'adressage est relativement simple : une simple expression régulière sur la ligne de code suffit. Certaines mnémoniques sont des cas particuliers d'instructions-machine plus générales : on parle de pseudo-instructions. Par exemple, sur les processeurs assez anciens qui utilisent le jeu d'instruction MIPS, l'instruction MOV r1 → r2 est synthétisée à partir de l'instruction suivante : add r1, r0, r2. Dans ces conditions, la table des mnémoniques ne contient pas l'opcode de l'instruction, mais littéralement une bonne partie de la représentation binaire de l'instruction, avec des opérandes (ici, des noms de registres) déjà spécifiés. Un champ pseudo-instruction est ajouté dans la table des opcodes pour savoir si seul l'opcode doit être remplacé ou non.
Symboles locaux
[modifier | modifier le wikicode]Pour traduire les symboles locaux, le logiciel d'assemblage utilise une table des symboles, qui mémorise les correspondances entre un symbole (un label le plus souvent) et sa valeur/adresse. Pour chaque symbole, cette table mémorise diverses informations, dont le nom du symbole, sa valeur et son type. La table des symboles est sauvegardée dans le fichier objet, vu qu'elle servira par la suite pour la relocation au niveau du linker et du loader. Pour remplir la table des symboles, le logiciel d'assemblage doit savoir quelle est l'adresse de l'instruction qu'il est en train de traduire. Pour cela, il suffit de profiter du fait que le logiciel d'assemblage traduit une ligne de code à la fois : le logiciel d'assemblage utilise un simple compteur, mis à zéro avant le démarrage de la traduction, qui est incrémenté de la taille de l'instruction après chaque traduction.
Il se peut que la valeur d'un symbole soit définie quelques lignes plus bas. Le cas le plus classique est celui des branchements vers une ligne de code située plus loin dans le programme. Toute instruction qui utilise un tel label ne peut être totalement traduite qu'une fois la valeur du label connue. Pour résoudre ce problème, il existe deux méthodes : la première correspond à celle des logiciels d'assemblage à deux passes, et l'autre à celle des logiciels d'assemblage à une passe.
Les assembleurs à deux passes sont les plus simples à comprendre : le logiciel d'assemblage parcourt une première fois le code ASM pour remplir la table des symboles et repasse une seconde fois pour traduire les instructions. Ces assembleurs font face à un léger problème sur les processeurs dont les instructions sont de taille variable : lors de la première passe, le logiciel d'assemblage doit déterminer la taille des instructions qu'il ne traduit pas, afin de mettre à jour le compteur d'adresse. Et cela demande d'analyser les opérandes et de déterminer le mode d'adressage de l'instruction.
Les assembleurs à une passe fonctionnent autrement : ceux-ci vont passer une seule fois sur le code source. La table des symboles de ces assembleurs contient, en plus des correspondances nom-valeur, un bit qui indique si la valeur du symbole est connue et une liste d'attente, qui contient les adresses des instructions déjà rencontrées qui ont besoin de la valeur en question. Quand ils rencontrent une référence dont la valeur n'est pas connue, ils ajoutent le symbole à la table des symboles et l'adresse de l'instruction dans la liste d'attente, et poursuivent le parcours du code source. S'ils rencontrent une instruction qui utilise ce symbole à valeur inconnue, l'adresse de l'instruction est ajoutée à la liste d'attente. Quand la valeur est enfin connue, le bit de la table de symboles est mis à 0 (pour indiquer que la valeur est connue), et le logiciel d'assemblage met à jour les instructions mémorisées dans la liste d'attente. Cette méthode pose cependant quelques problèmes sur les processeurs dont les instructions sont de taille variable.
Noms de registres et autres constantes
[modifier | modifier le wikicode]On pourrait penser qu'il existe une table de correspondance pour les noms de registres, comme la table de mnémoniques pour les mnémoniques, mais on peut ruser en considérant les noms de registres comme des symboles comme les autres : il suffit de remplir la table des symboles avec les correspondances nom de registre → représentation binaire, et le tour est joué. On peut utiliser le même principe pour gérer les préfixes des instructions, comme sur le jeu d'instruction x86.
Optimisation
[modifier | modifier le wikicode]
Il n'est pas rare que le code assembleur soit optimisé avant d'être traduit en langage machine. D'autres assembleur optimisent directement le code objet crée. Ces optimisations sont relativement rudimentaires. Il s'agit le plus souvent de remplacement d'instructions lentes par des instructions équivalentes mais plus rapides. Par exemple, il est possible de remplacer des multiplications ou divisions par une puissance de deux par des décalages, plus rapides. Le logiciel d'assemblage peut aussi modifier l'ordre des instructions pour profiter au mieux du pipeline. Dans tous les cas, ces optimisations sont prises en charge à part, soit dans une passe d'optimisation du code assembleur, soit par un logiciel annexe au logiciel d'assemblage, qui optimise directement le code objet.
L'édition des liens
[modifier | modifier le wikicode]
De nos jours, les programmes actuels sont composés de plusieurs modules ou classes, qui sont traduits chacun de leur côté en fichier objet. Les symboles globaux, qui référencent une entité déclarée dans un autre fichier objet, ne sont pas traduits en adresses par le logiciel d'assemblage. Pour obtenir un fichier exécutable, il faut combiner plusieurs fichiers objets en un seul fichier exécutable, et traduire les symboles globaux en adresses : c'est le but de la phase d'édition des liens, effectuée par un éditeur de liens, ou linker.
En l'absence de segmentation mémoire (une forme de mémoire virtuelle), le linker concatène les fichiers objets. Avec la segmentation, chaque fichier objet a ses propres segments de code et de données, qui doivent être fusionnés. Pour faire son travail, le linker doit savoir où commence chaque segment dans le fichier objet, son type (code, données, etc.), et sa taille. Ces informations sont mémorisées dans le fichier objet, dans une table de segments, créée par le logiciel d'assemblage. De plus, le linker doit rajouter des vides dans l'exécutable pour des raisons d'alignement au niveau des pages mémoire.
 |
 |
Relocation
[modifier | modifier le wikicode]Combiner plusieurs fichiers objets en exécutable va poser un problème similaire à celui obtenu lors du lancement d'un programme en mémoire : les adresses calculées en supposant que le fichier objet commence à l'adresse 0 sont fausses. Pour corriger celles-ci, le linker doit effectuer une relocation, et considère que le début du fichier exécutable est à l'adresse 0. Pour cela, le linker doit connaître l'emplacement des adresses dans le fichier objet, informations qui sont mémorisées dans la table des symboles sauvegardée dans le fichier objet.
Résolution des symboles globaux
[modifier | modifier le wikicode]De plus, le linker s'occupe de la résolution des symboles globaux. En effet, quand on fait appel à une fonction ou variable localisée dans un autre fichier objet, la position de celle-ci dans le fichier exécutable (et donc son adresse) n'est pas définie avant son placement dans le fichier exécutable : la table des symboles contient des vides. Une fois la fusion des fichiers objets opérée, on connaît les adresses de ces symboles globaux, qui peuvent être traduits : le linker doit donc mettre à jour ces adresses dans le code machine (c'est pour cela qu'on parle d'édition des liens).
Les chargeurs de programme
[modifier | modifier le wikicode]Au démarrage d'un programme, un morceau du système d'exploitation, le chargeur de programme ou loader, rapatrie le fichier exécutable en RAM et l'exécute. Sur les systèmes sans mémoire virtuelle, le loader vérifie s'il y a suffisamment de mémoire pour charger le programme. Pour cela, il a besoin de savoir quelle est la taille du code machine et de la mémoire statique, ces informations étant mémorisées dans l'exécutable par le linker.
Loaders absolus
[modifier | modifier le wikicode]Sur les systèmes d'exploitation mono-programmés, il était impossible d'exécuter plusieurs programmes en même temps. Ces systèmes d'exploitation découpaient la mémoire en deux parties : une portion de taille fixe réservée au système d'exploitation et le reste de la mémoire, réservé au programme à exécuter. Avec cette technique, l'adresse du début du programme est toujours la même : les loaders de ces systèmes d'exploitation n'ont pas à gérer la relocation, d'où leur nom de loaders absolus. Les fichiers objets/exécutables de tels systèmes d'exploitation ne contenaient que le code machine : on appelle ces fichiers des Flat Binary. On peut citer l'exemple des fichiers .COM, utilisés par le système d'exploitation MS-DOS (le système d'exploitation des PC avant que Windows ne prenne la relève).
Quand les programmes consistaient en un seul fichier assembleur de plusieurs milliers de lignes de code, il était possible de les traduire en langage machine et de les lancer directement. Le logiciel d'assemblage était un assemble-go loader, un assembleur à une passe qui écrivait le code machine directement en RAM. Il n'y avait alors pas besoin d'édition des liens et le loader était fusionné avec le logiciel d'assemblage.
Loaders à relocation
[modifier | modifier le wikicode]Avec le temps, les systèmes d'exploitation sont devenus capables de faire résider plusieurs programmes en même temps dans la RAM de l'ordinateur, ce qui demanda au loader de s'occuper de la relocation. Le loader doit donc savoir où sont les adresses dans le fichier exécutable, histoire de les « relocaliser ». Pour cela, il se base sur une table de relocalisation qui indique la localisation des adresses dans le fichier exécutable. Cette table est généralement une copie de la table des symboles, à quelques différences près : pour chaque label, on a ajouté un bit qui indique si l'adresse correspondante doit être relocalisée. Les assembleurs à deux passes peuvent produire une telle table sans aucune modification, ce qui n'est pas le cas des assembleurs habituels à une seule passe.
Avec la multiprogrammation, il est devenu possible de démarrer plusieurs copies d'un même programme simultanément. Dans ce cas, il est possible de partager certains segments du code machine entre les différentes copies du programme. Pour cela, le loader doit savoir où se situent le code machine et les données statiques dans le fichier exécutable, ce qui demande de sauvegarder ces informations dans le fichier exécutable. Ces informations sont mémorisées dans un en-tête, qui mémorise la position et la taille des autres segments dans le fichier (avec souvent d'autres informations).
Sur certains processeurs, la relocation est totalement gérée en matériel, à l'intérieur du processeur. C'est notamment le cas pour les ordinateurs qui utilisent la mémoire virtuelle. Sur ces ordinateurs, les loaders ne font que modifier la table des pages pour faire croire que le fichier exécutable est « swappé » sur le disque dur : le chargement du programme se fera à la demande, quand un chargement d'instruction déclenchera un défaut de page (page miss). Certains processeurs ont tenté d'être encore plus novateurs, en se payant le luxe de supprimer aussi l'étape d'édition des liens. Sur ces processeurs, l'attribution d'une adresse à un objet est déterminée au cours de l'exécution du programme, directement au niveau matériel. Mais ces architectures, dites à arithmétique à zéro adresse (Zero address arithmetic), sont cependant très rares.
Loaders à édition des liens dynamique
[modifier | modifier le wikicode]Les librairies partagées sont des librairies mises en commun entre plusieurs programmes : il n'existe qu'une seule copie en mémoire, que les programmes peuvent utiliser au besoin. Les librairies statiques ont toujours la même place en mémoire physique : pas besoin de relocation ou de résoudre les labels qui pointent vers cette librairie. Avec les librairies dynamiques, la position de la librairie en mémoire varie à chaque démarrage de la machine : il faut faire la relocation, et résoudre les labels/symboles de la librairie.
Dans certains cas, l'édition des liens s'effectue dès le démarrage du programme, qui doit indiquer les librairies dont il a besoin. Mais dans d'autres cas, le programme charge les librairies à la demande, en appelant le loader via une interruption spéciale : il faut alors passer le nom de la librairie à exécuter en paramètre de l'interruption.
Pour aller plus loin
[modifier | modifier le wikicode]- Livre Assemblers and loaders, disponible gratuitement via le lien suivant : Assemblers and loaders ;
- Livre Linkers and Loaders de John R. Levine, publié par by Morgan-Kauffman, (ISBN 1-55860-496-0).